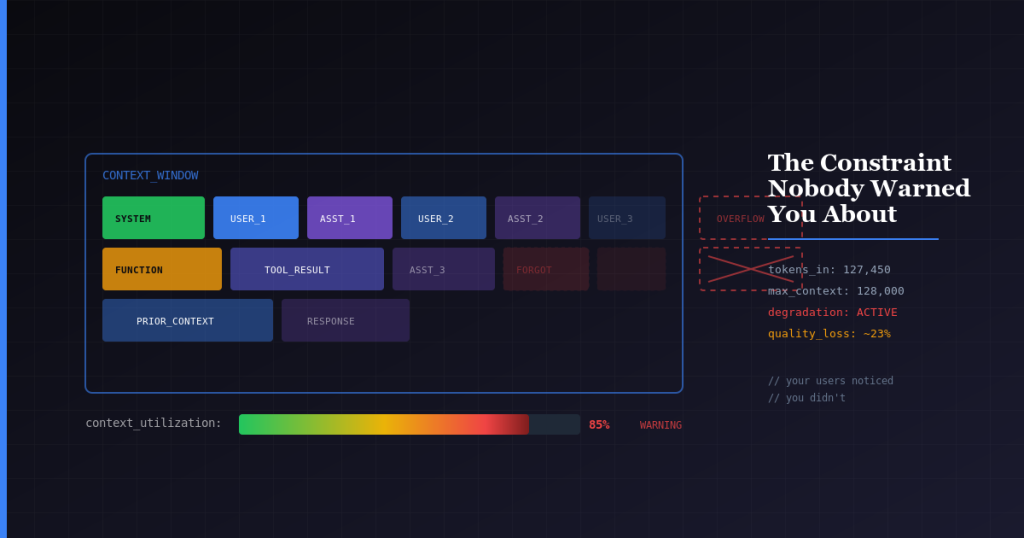
Your LLM will forget things. Important things. And it won’t tell you when it happens.
I learned this the expensive way after 15 years building fintech systems. Context windows are the new memory constraint, and almost nobody is architecting for them.
The Silent Failure Mode
In traditional software, memory constraints cause crashes and hard failures. You get alerts, something breaks visibly, and you know there’s a problem to fix.
Context window limits don’t work like that. They degrade silently. The model stops considering older information and comes back with worse outputs that still look plausible. There’s no error message telling you something went wrong.
This is what makes it dangerous. Your system keeps running, users keep getting responses, but the quality rots from the inside.
What Actually Happens in Production
Here is a scenario I have seen break production systems.
A customer uploads a 50-page contract. Your system summarizes the first 30 pages beautifully with clear structure and good extraction. But the model quietly ignores the liability clauses on page 47 and the indemnification language on page 49.
Nobody notices until legal does. By then, the damage is done.
This pattern repeats across every domain where documents exceed a few thousand tokens. Healthcare records, financial disclosures, legal agreements. The model processes what fits in its attention and gracefully forgets the rest.
The 128K Marketing Problem
Model providers love advertising large context windows. 128K tokens, 200K tokens, a million tokens.
What they don’t tell you is that while you can fit 128K tokens into the window, you won’t get good results across all of them. Research shows that retrieval quality degrades in the middle of long contexts because models pay more attention to the beginning and end. This is called the “lost in the middle” problem and it’s well documented.
Teams keep ignoring it because the marketing says 128K and the demo worked fine with a 2-page document. Production traffic is not a demo.
RAG Does Not Solve This
The common response is “just use RAG” as if retrieval augmented generation fixes everything. It doesn’t. It shifts the problem.
Instead of worrying about context limits, you’re now worrying about chunking strategy, embedding quality, retrieval accuracy, and reranking. The whole pipeline has to work correctly or you pull the wrong chunks.
If you miss the relevant chunk, the model confidently answers using whatever it did retrieve. It doesn’t say “I could not find that information.” It makes do with what it has and sounds authoritative doing it.
I have built RAG pipelines in production. The tradeoff is real. You’re not eliminating the memory problem, you’re distributing it across a more complex system with more failure modes. Sometimes that tradeoff makes sense, sometimes it doesn’t. But calling it a solution is overselling it.
Multi-Turn Conversations Are Worse
Single-request context limits are manageable once you know about them. Multi-turn conversations are where things get ugly.
Every message adds tokens. System prompts, prior user messages, prior assistant responses, function calls and their results, tool definitions. It accumulates faster than you expect.
By turn 15 of a conversation, you’re either truncating history or hitting limits. Either way, the AI forgets what the user said earlier. The user notices because they referenced something from turn 3 and the model acts like it never happened. Trust erodes quickly.
You probably won’t notice until you dig into support tickets or churn data. Users don’t complain that “the context window truncated.” They say “the AI is dumb” and leave.
What Actually Works
After hitting these walls repeatedly, here is what we do now.
1. Observability: We instrument token counts at the middleware layer before every LLM call. We log input tokens, output tokens, and total context utilization to Datadog and set up dashboards that show p50, p95, and p99 token usage per endpoint.
Cost tracking alone doesn’t tell you when you’re approaching degradation, but token-level observability does.
2. Alterting: We set alerts at 70% context utilization, not 100%. We use a custom metric that calculates (system_prompt_tokens + conversation_history_tokens + current_request_tokens) / max_context_window and fires a warning when it crosses threshold. By the time you hit the limit, quality has already degraded. You want early warning, not a post-mortem.
3. Rolling Summarization: We run rolling summarization using a smaller model like GPT-4o-mini to compress conversation history after every 5 turns. The summary gets stored in a session object and replaces raw history, keeping the context lean while preserving key facts. We also extract structured metadata like user intent, entities mentioned, and decisions made into a JSON blob that persists separately from the conversation flow.
4. Load Testing: We load test with production-scale documents. Our staging environment ingests real anonymized contracts and financial documents in the 40K-60K token range. If your CI pipeline only tests with 500-token sample inputs, you’re not testing the system that runs in production.
5. Prompt Structure: We structure prompts to front-load and back-load critical information. System instructions go at the top, the current user query goes at the bottom, and we keep the middle for context that can tolerate some attention decay.
For RAG, we rerank retrieved chunks and place the highest-relevance chunks at the boundaries of the context window, not buried in the middle.
The Mental Model Shift
Traditional software taught us that memory is plentiful and you can optimize later if needed. For decades, we could be sloppy about it because RAM got cheaper and machines got bigger.
Context windows don’t work like that. You can’t buy a bigger context window for a specific model. You work within the constraint or you architect around it.
The teams that get this right treat context windows like database connections: a limited resource that requires pooling, monitoring, and explicit management. You would never open unlimited database connections and hope for the best. Don’t do it with context windows either.
The Bottom Line
Building AI products requires unlearning old assumptions. “Memory is cheap” was true for decades but it’s not true for context windows.
Your most critical constraint is how much your model can hold in its head at once. Every architectural decision should account for it.
Plan for it, or find out in production like I did.
Debjit (Dev) Saha is CTO at Ziffy.ai and a fractional CTO for Seed to Series B startups. He writes about building AI systems that actually work in production.